

This article written by Jon Young and Geoff Tritsch originally appeared in the ACUTA 2014/2015 Winter Journal.
What is privacy? In a world where Netflix knows your taste in movies, Spotify and Pandora offer uncannily accurate suggestions about what music you’d like to hear, and your local grocery store knows what you had for dinner last week, the concept of “privacy” has changed dramatically.

We may not be able to describe exactly what constitutes privacy these days, but most people can tell you what it feels like when it’s been invaded. People of different cultures, customs and nationalities may have widely varying expectations about what privacy is and what it should apply to but most everyone agrees that there is certain information that should remain strictly private
Technology has changed dramatically, and the ways in which privacy is protected – and violated – have changed right along with it. Conversations have always been vulnerable to eavesdropping; letters have been steamed open for centuries; phone calls can be monitored. But in the age of technology, such invasions have given way to more sophisticated intrusions. Text messages can be intercepted; computers can be hacked; identities can be stolen; credit card numbers can be acquired – sometimes en masse. Any discussion about technology quickly touches on issues of privacy, and modern technology can’t always tell the difference between good guys and bad guys. We may not even agree on who the good and bad guys are.
Our Lives Are Online
With so many routine tasks such as banking, shopping, and paying bills moving online, identity theft has become one of the 21st Century’s most troublesome crimes. There has always been a battle between those who want to maintain privacy and those who want to exploit vulnerabilities for their own ends. That battle has moved into cyberspace.
The legal landscape is constantly adapting, yet never quite catches up with technology’s rapidly evolving capabilities. Complex and sometimes conflicting laws and regulations must be upheld by the various organizations and business concerns entrusted with protecting private information. Combining the legal landscape with our perceived ethical obligations is far easier to say than it is to do.
Privacy; Security; Confidentiality – these are the issues of the modern age. The public’s right to know vs. the individual’s right to control. The Internet’s insatiable hunger for information vs. every individual’s right to privacy. Organizations want to prosper and grow, and our society thrives when our education and commerce do.
Education and commerce have moved online and security breaches pose a threat for educational institutions, business entities, and individuals alike. These complex issues and intertwined concepts must be better understood – and addressed. A good place to start is to consider the terminology we use to discuss them: privacy versus confidentiality versus security.
Defining Our Terms
In simple terms, privacy applies to people; confidentiality applies to data; and security is the effort we put forth in order to maintain confidentiality. Sounds simple enough, but these terms can quickly get confused, especially when we define one in terms of another. Privacy consists of confidential information which must be kept secure. But the concept of what is private is complex – and malleable – often changing with each new situation and context.
For example, let’s say that I consider my salary to be private. I choose to share that information with my spouse, my accountant, my financial planner, and various governmental entities that compel me to reveal it. I nonetheless choose to keep it confidential from my colleagues, my family and the rest of the world – and I expect those with whom I share it to do the same.
However, if I were employed by certain state agencies or institutions, I might be compelled to reveal my salary as well as other “private” information. Though I would prefer confidentiality, the laws of the state employing me may override my preferences. On the other hand, maybe I make a great salary and like to brag. Same information; different context; different requirements and results.
As educational institutions, we have access to a broad range of information that must remain confidential; a broader pool of information that should remain confidential: and an even broader set that might be considered private. Volumes of potentially confidential information pass through the networks and phone systems we manage every day and we typically have the power to access them with ease.
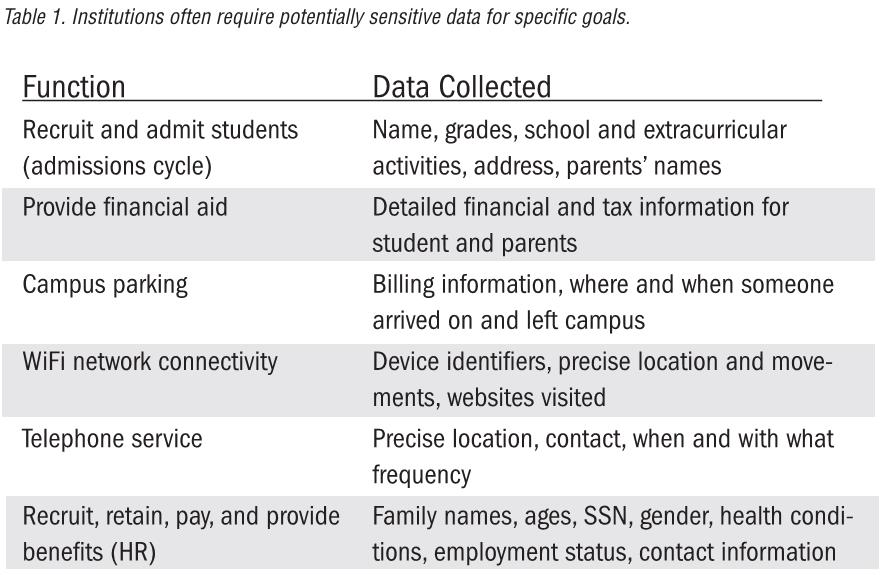
We can’t refuse to accept private and proprietary information. It is a basic necessity for many functions on campus. Examples of institutional functions requiring the collection of private data and examples of potentially sensitive data associated with those goals include:
Consider this data in aggregate – we could know exactly where each person was on campus at any given time, what websites they visited, when and for how long they were online, who they communicated with, how much money they make, what financial institutions they bank with, their spouse’s name, sex, age, family health history, childhood activities, and more – and could correlate it all into an accurate personal profile.
Quis Custodiet Ipsos Custodies?
As the owners and operators of enterprise systems that collect such data – and the networks over which information passes – we have a tremendous responsibility to protect this information, even as we perform the following multiple and sometimes competing roles:
- Maintain the confidentiality of our institution’s data.
- Assist our users in keeping their data confidential.
- Maintain the privacy of individuals our institution collects data about/from.
- Ensure the effective operation and security of our network and systems.
Our ability to maintain privacy is contingent on our ability to secure confidential information and keep our networks secure. But our ability to keep our systems and networks running effectively and to keep the network secure is by monitoring the (often private) information that crosses our networks.
We have to trust that those who watch the network are more interested in maintaining its integrity than they are with the information running across it – a dynamic that leads to this age-old question: Quis custodiet ipsos custodes? Who watches the watchers?
Consider What You Collect
With ever-greater amounts of confidential data being generated, the need for a privacy policy is beyond question. Yet, remarkably, few institutions actually have one in place. And for those that do, those policies often fail to encompass the full spectrum of privacy related issues.
Key to the effectiveness of any privacy policy is the need to strike a balance between institutional needs and the potential impact on everyone’s privacy in the event of a security breach Our natural inclination is to collect and retain everything. But even seemingly innocuous information can create privacy issues when revealed or mined, especially in combination with other seemingly innocuous information.
Could a seemingly “safe” piece of information be combined with other similarly “harmless” bits of data to ultimately expose information someone considers confidential? And if that’s possible, does the potential future value of institutional data collection outweigh the risk of an invasion of personal privacy? Would the person whose privacy is in question give a different answer? The answer to these questions may trigger another: should we limit data collection to those areas that have specific and immediate value?
If some of the data being collected has no immediate value, is it worth the potential privacy risk to collect it? Why collect it at all? We need to carefully examine these issues, the potential privacy implications, and the institutional risk were that data to be breached or used in some inappropriate or illegal way.
How long should we retain the data we collect? When and how do we purge data that is no longer necessary? For example, if we compile call detail records (CDR) for billing and fraud purposes, should we purge that CDR data after the bills have been paid and some reasonable period of time has gone by to contest those bills?
CDR data clearly has potentially confidential information in it, such as calls to or from mental health facilities, family planning clinics, divorce attorneys, etc. These are important considerations that must be addressed by any organization responsible for maintaining and operating data-rich online systems. The educational community must stay ahead of the curve as even more functionality and sensitive information migrates online.
Privacy Impact Assessment
One way institutions can answer these important questions is by creating a Privacy Impact Assessment (PIA). This worthwhile tool identifies and assesses the privacy risks that exist when an organization collects, uses, shares and stores any individual’s personal information. PIAs provide a process to assess the privacy ramifications of data collection and ensure that security protocols effectively support the privacy policies, regulations, and compliance goals set by the institution.
There are many examples of PIA methodologies available online. However, if you do a web search for “Privacy Impact Statement” you will quickly see that the phrase lends itself to a wide array of applications and implementations. Yours need not be onerous. By adapting the examples online and overlaying your institutional culture, you can create a process that will serve your organization in a clear and straightforward manner.
As with so many other discussions about defining and achieving institutional goals, this brings us back to setting and maintaining policy. A privacy policy should set expectations for both the data collector and the “owner(s) of the data.” The expectations for all parties should be a privacy policy that is:
- Reasonable
- Clear
- Agreed upon
- Articulated
- Documented
- Auditable
That question was recently posted on the Educause CIO mailing list, generating a variety of interesting responses and a number of further questions. To turn the question around, if we create rules that say we won’t retain certain types of data; that we will restrict who has access to what we retain; and that we will purge data after a specified period, what controls have we implemented to ensure these obligations are being met and how can we audit that?We in IT often fail in one or more of these areas, but the auditable element is probably the most difficult to implement. Consider that many of us have negotiated into third-party contracts that contain provisions about how our institutional or end-user data will be managed. Examples might include the common provision in the Google Apps for Education environment assuring us that our user’s email will not be mined for any purpose. How do we audit that this obligation?
From CISOs to CPOs
By now many (most?) institutions have a Chief Information Security Officer (CISO), be it full-time with a staff, a solo effort, part time faculty or shared with other institutions. Few institutions of higher learning – except for some of the largest – have a Chief Privacy Officer (CPO). But aside from sheer quantity of information, privacy issues bear little relationship to institutional size.
The role of the CPO should be to assist in raising awareness, develop institutionally appropriate policies and to act as the advocate for privacy for the campus. Given the nature of the role, it may be appropriate to recruit a faculty member with subject matter expertise as a part-time CPO. Despite the potential conflict of interest, we have even seen some institutions tap their CISO as the CPO effectively.
It is Vantage’s overarching view that privacy must be viewed from the context of what is:
- Legally mandated
- Ethically appropriate (not always in agreement with the law)
- Supportive of the institutional mission
- Appropriate to the campus culture
Historically, and for a number of practical reasons, IT personnel have often made decisions about what their institution should do regarding privacy. Those decisions were often based on what best fit the operational goals and limitations of the IT group. This can no longer be the case. Privacy is an institutional governance and cultural issue. IT should serve as an implementer and advisor, certainly, but should not be setting policy. IT must retain its key role of being the subject matter expert, a strong privacy advocate, and the potential driver in encouraging institutional leaders to consider privacy objectives and policies. But the stakes are too high and the costs of failure too dear to have IT go it alone when privacy matters so much.